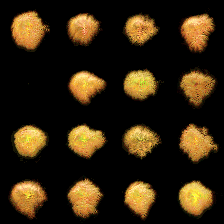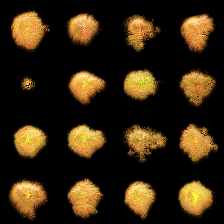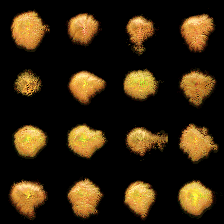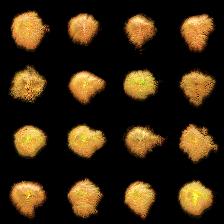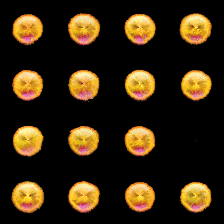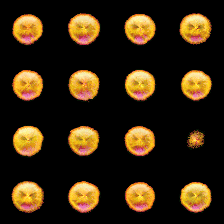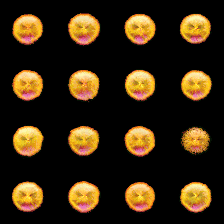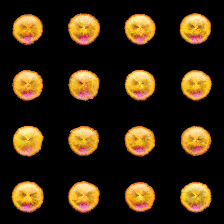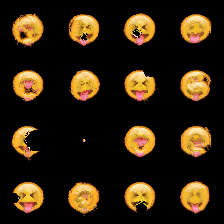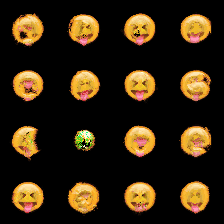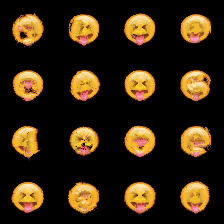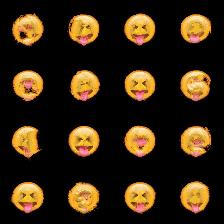In this blog post, I will be sharing my replication and exploration findings about Neural Cellular Automata (NCA) inspired by the original Distill article (Mordvintsev et al. 2020). The article discusses the fascinating concept of morphogenesis, which sparked my interest and motivated me to explore it further. As a result, I experimented to implement the NCA algorithm using Jax, a powerful machine learning library.
Morphogenesis is the process by which life develops from a single cell into complex shapes and forms. While the NCA algorithm does not capture all the intricacies of this process due to our limited understanding, it provides an interesting and enjoyable way to visualize emoji generation and its ability to regenerate after damage. In this post, I will discuss the challenges I encountered while implementing the NCA algorithm and present several plots to showcase its functionality.
You can find the accompanying Jax code for the Neural Cellular Automata implementation on GitHub: NCA code
Exploring the Neural Cellular Automata Algorithm
The Neural Cellular Automata (NCA) algorithm operates on a state grid, S \in \mathbb{R}^{H \times W \times C}. Here, H and W represent the grid’s height and width respectively, while C stands for the number of channels. The initial four channels correspond to RGB and alpha channels while the remaining channels denote the cell states.
The state grid undergoes an update at each time step t. This process involves altering each cell within the grid following the principles of the NCA algorithm, which can be broken down into three distinct steps:
Perception: Each cell assesses its current state and the states of its neighbors, accomplished through the use of gradients.
State Update: Using the information from the perceived state, each cell updates its state under the guidance of a neural network.
Aggregation: This step comprises two parts; firstly, not every cell undergoes an update at each time step. Secondly, updates are exclusively reserved for ‘alive’ cells.
In the forthcoming sections, we’ll take a closer look at each of these steps, elaborating on their significance and functionality within the framework of the NCA algorithm.
Perception module
In the perception state each cell perceives solely its intrinsic state as well as the gradients of the cell state in both the x and y directions. The Sobel operator is applied to each channel, both in the x and y directions, and the resultant output is then combined with the original cell state. The cell state, initially a 16-dimensional vector, transforms into a 48-dimensional vector following this perception module. We express the perception at time t as P_t.
In this context, \mathbf{S}_t represents the state of the cell at time t. The perceive function is designed as a concatenation operation, wherein the Sobel operator is applied to each channel within the cell state.
Here, \mathbf{K}_x and \mathbf{K}_y denote the Sobel kernels in the x and y directions, respectively. The convolution operation is performed on each channel present within the cell state. These Sobel kernels are characterized as follows:
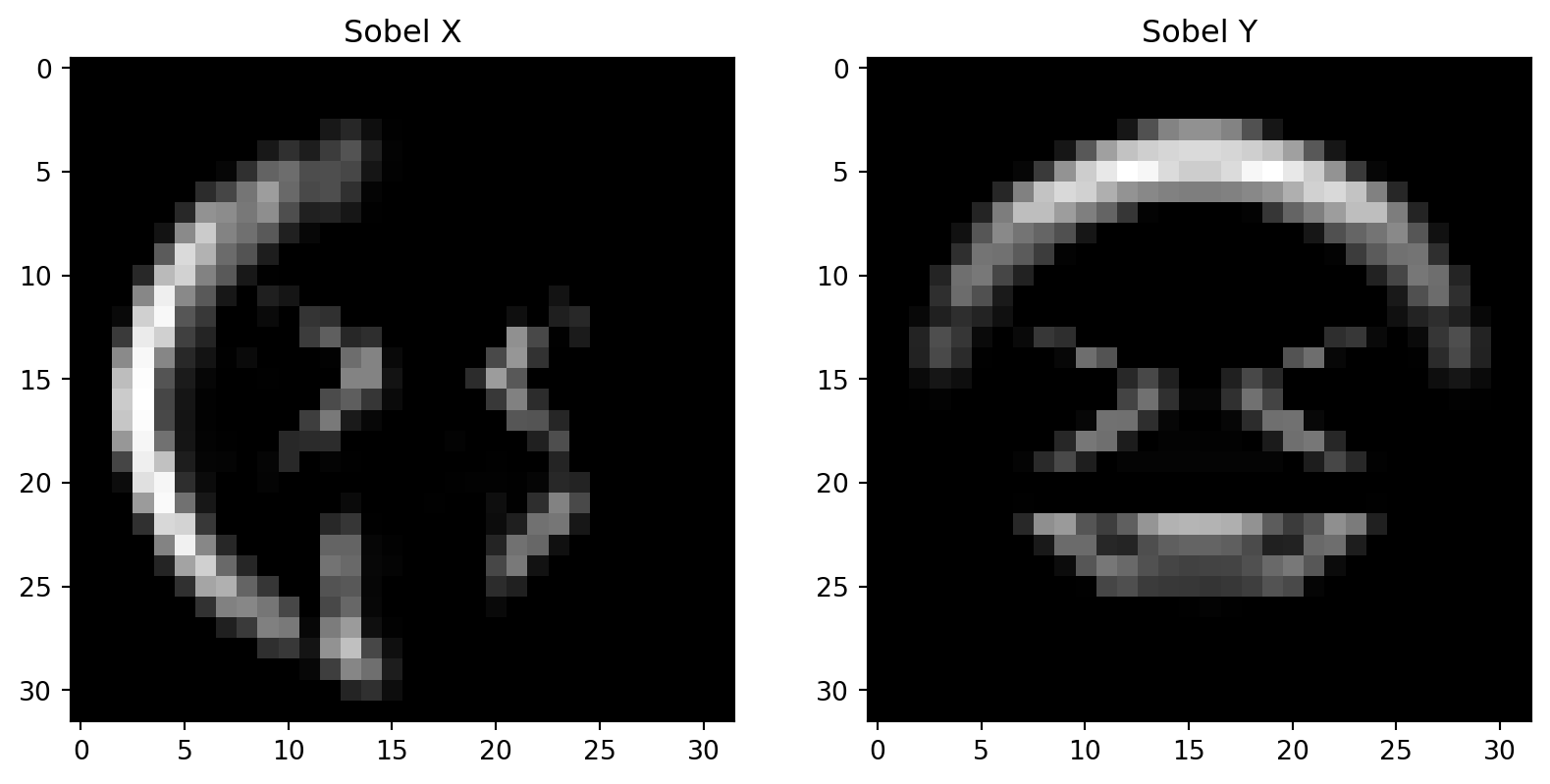
Let’s bring the Sobel operators to life with a visualization. As our test subject, we’ll be using the widely recognized smiley emoji, specifically the one sticking its tongue out - 😝. This will serve as our input image:
Code
import syssys.path.append('NCA')import NCA.nca.model as modelimport NCA.nca.nca as ncaimport cv2import matplotlib.pyplot as pltimport numpy as npimport plotly.express as pxfrom plotly.subplots import make_subplotsimport plotly.graph_objects as goemoji_path ='NCA/emoji_imgs/smile.png'img = cv2.imread(emoji_path, -1)# mult by alphaimg_alpha = img[:,:,3] >0img = img[:,:,:3] * img_alpha[:,:,None]img = img.astype(np.uint8)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = cv2.resize(img, (32,32))kernel_x, kernel_y = nca.create_perception_kernel(input_size=3, output_size=3)# transpose img into CHW img = np.expand_dims(img, axis=0)/255.img_t = img.transpose(0,3,1,2)# nca.perceive expects nchw perceive_out = nca.perceive(img_t, kernel_x, kernel_y) *255# transpose back to NHWCperceive_out = perceive_out.transpose(0,2,3,1).astype(np.uint8) rgb = perceive_out[0,:,:,0:3]sobel_x = perceive_out[0,:,:,3:4]sobel_y = perceive_out[0,:,:,6:7]# Plot the img and the sobel imgs in x and y# Plot the img and the sobel imgs in x and yfig, axs = plt.subplots(1, 2, figsize=(10, 10))# Remove the axis for the top-right subplot, which will remain empty# Plot the images#axs[0, 0].imshow(rgb)axs[0].imshow(sobel_x[:,:,0], cmap='gray')axs[1].imshow(sobel_y[:,:,0], cmap='gray')# Add some captions#axs[0, 0].set_title('RGB')axs[0].set_title('Sobel X')axs[1].set_title('Sobel Y')# Adjust the spacing between the subplotsplt.show()
Thus, each cell perceives solely its intrinsic state as well as the gradients of the cell state in both the x and y directions.
The update module
The update component, represented as U, is a basic Multilayer Perceptron (MLP) that responds to the perceived state S_t by generating an update for the cell state. Here’s how we define the update module:
In this context, \text{Update}(x) = \text{MLP}(x) represents a multilayer perceptron comprising several hidden layers, each containing 128 neurons and utilizing ReLU activation. The output of the MLP is a 16-dimensional vector, which serves as the modification for the cell state.
We can define the comprehensive update function as follows:
\begin{align}
\mathbf{S}_{t+1} &= \mathbf{S}_t + \mathbf{U}(\mathbf{S}_t) \Delta t \\
\end{align}
Here, \Delta t symbolizes the incremental time step.
Stochastic update
In an attempt to emulate the inherent randomness of real-life scenarios, the authors introduce a stochastic update function. Each cell has a 50% chance of updating its state at each time.
Code
# create a random statep =0.5random_state = np.random.uniform(0., 1., size=rgb.shape[:2]) rgb = np.asarray(rgb)rgb_random_update_25p = rgb.copy()rgb_random_update_50p = rgb.copy()rgb_random_update_75p = rgb.copy()#print(f'random state shape : {random_state.shape}')#print(f'rgb shape : {rgb.shape}')color = (0, 128, 250)rgb_random_update_25p[random_state >0.75] = color rgb_random_update_50p[random_state >0.5] = color rgb_random_update_75p[random_state >0.25] = color # plot the 50 and 75 percent random updatefig, axs = plt.subplots(1, 3, figsize=(10, 10))# Remove the axis for the top-right subplot, which will remain emptyaxs[0].axis('off')axs[1].axis('off')# Plot the imagesaxs[0].imshow(rgb_random_update_25p)axs[1].imshow(rgb_random_update_50p)axs[2].imshow(rgb_random_update_75p)# Add some captionsaxs[0].set_title('25% random update')axs[1].set_title('50% random update')axs[2].set_title('75% random update')# Adjust the spacing between the subplotsplt.show()
In the depicted diagrams, we observe the effects of varying update rates on a random state. The leftmost plot demonstrates a 25% update rate, the central one exhibits a 50% rate, and the rightmost chart reveals the impacts of a hefty 75% update rate.
Updating Living Cells
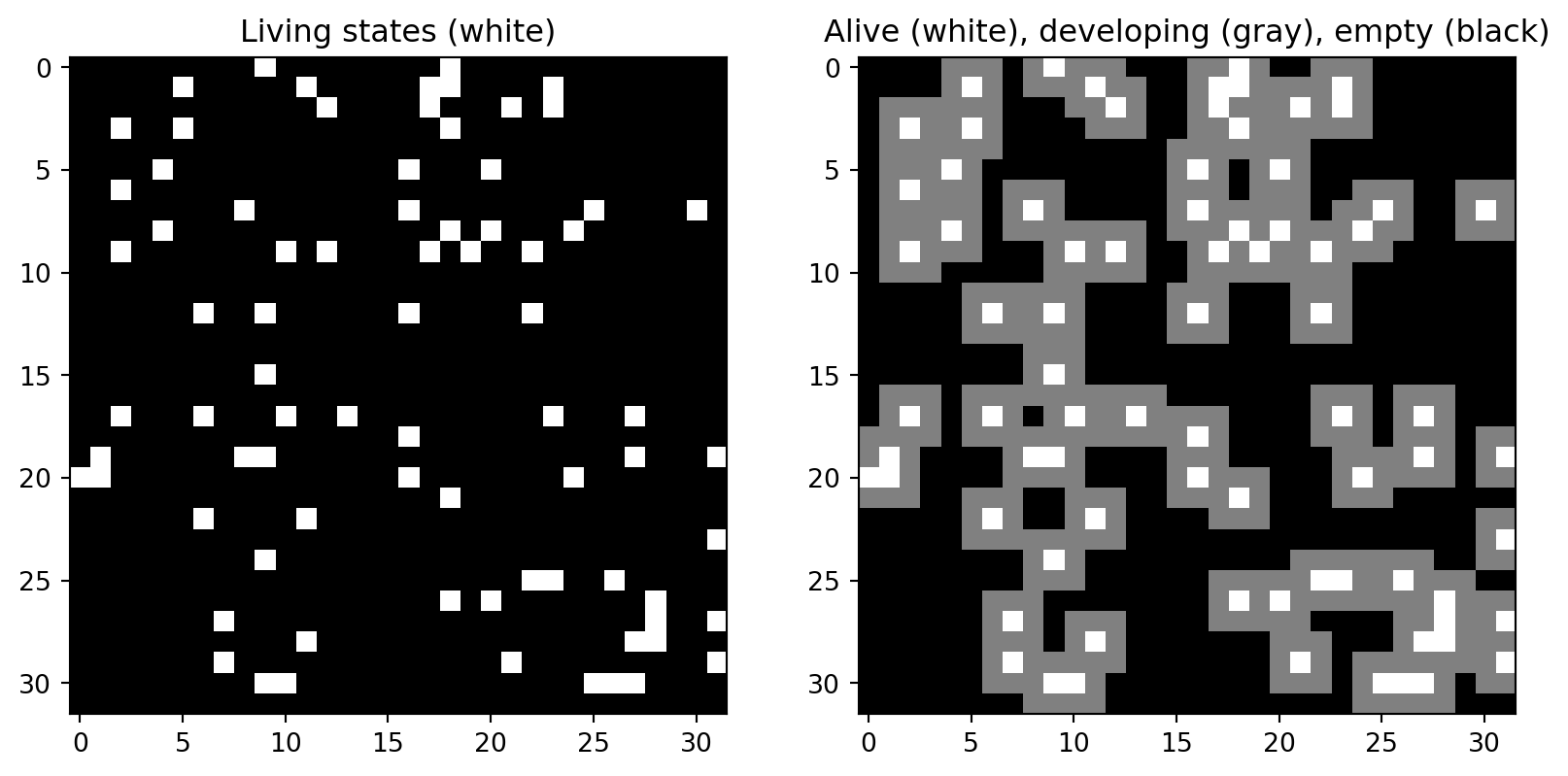
The authors classified cells into three categories: “mature,” “developing,” and “empty.” - where only the mature and developing cells are updated. This classification is determined by applying a max-pooling operation to the alive channel of the state grid (the alpha channel) and using a threshold of 0.1. The resulting cell types are as follows:
Mature (alive): If the max-pool value exceeds the threshold.
Developing: If the max-pool value is below the threshold.
Empty: If the max-pool value is zero.
In the plot on the left, the white cells indicate mature cells. The plot on the right depicts the alpha channel after applying the living cell update, where white cells represent mature cells, and gray color indicates developing cells.
Given that the NCA behaves similarly to an LSTM with recurrent connections, forming a computational graph with a large number of NCA updates is not feasible. Instead, the authors employed a sample pool strategy to address this issue. After each training step, the output samples are placed into a pool (or buffer), and a random batch of samples is drawn from this pool as input for the next training step. However to ensure that the NCA can still regenerate from the seed state, the highest loss state within a batch is replaced with the seed state. This approach helps maintain a diverse range of states in the sample pool while ensuring efficient use of computational resources during training.
To prevent the model from forgetting how to generate more complex states, the seed state replaces the highest loss state within a batch. This approach helps maintain a diverse range of states in the sample pool while ensuring efficient use of computational resources during training.
(a) At step 1k
(b) At step 5k
(c) At step 10k
Figure 1: The states in the training batches were recorded at 1k, 5k, and 10k training steps, showcasing the evolution of the cellular automata (CA) for each batch at different stages.
Training for regeneration from damaged states
To enhance the NCA model’s ability to regenerate from damaged states, the authors introduced a training approach involving random cutouts. Without specific training for regeneration, the NCA model cannot effectively recover from a damaged state. To overcome this limitation, a random circular cutout is applied to the state, and the model is trained to regenerate the missing portion.
Challenges with training with random cutouts
During experimentation, I encountered difficulties when utilizing random cutouts for training. Specifically, when using a batch size of 16 and damaging four instances per batch, the model experienced gradient explosion. This issue arises due to the recurrent nature of the NCA model, making it prone to gradients becoming unstable. To address this problem, I attempted various techniques, including gradient clipping, reducing the number of NCA steps, and decreasing the learning rate. However, these approaches did not completely resolve the issue.
After conducting extensive trial and error, I determined that a batch size of 4, with only one state being damaged per batch, yielded optimal results for training the model to regenerate from damaged states.
Furthermore, the number of steps involved in the NCA algorithm during training with random cutouts plays a critical role. If the number of NCA steps is too low, the states in the sample pool become distorted, resulting in the entire pool being contaminated with numerous undesirable states. Consequently, regardless of the duration of model training, effective recovery becomes unattainable (see Figure Figure 2 (a)). However, by increasing the number of NCA steps, the NCA algorithm successfully learns to regenerate from damaged states (see Figure Figure 2 (b)).
(a) The figure depicts a training batch with a batch size of 16, employing 64 NCA steps.
(b) The figure depicts a training batch with a batch size of 4, employing 128 NCA steps.
Figure 2: Figure Figure 2 (a) illustrates that when employing a batch size of 16, the NCA model struggles to achieve successful regeneration. However, Figure Figure 2 (b) demonstrates that by utilizing a batch size of 4 along with a substantial number of NCA steps, the NCA model exhibits improved regeneration capabilities.
Upon completion of training, the NCA demonstrates its remarkable ability to regenerate itself even when subjected to significant damage. This is vividly illustrated in the accompanying gif, where the NCA successfully regenerates the left half of the emoji after its removal.
Figure 3: At around 10 seconds the left half of the state grid is completely removed
Looking deeper into the individual channels of the state grid
It was fascinating to observe the temporal changes in the values across the 16 channels, even though they lack any actual significance. The following plots depict the aforementioned example, wherein the left side of the state is damaged. I have generated plots for each of the 16 channels at three distinct locations within the state grid: the center of the emoji (28, 28), the midpoint between the center and the edge (28, 18), and finally, the edge of the emoji (28, 11).
Let’s begin with the center of the emoji at coordinates (28, 28). The plot showcasing the values at this central point reveals an extensive range spanning from -1700 to 1000. Moving towards the midpoint between the center and the edge, the values range between -25 and 30. Finally, at the point adjacent to the edge, the values vary within the range of -0.5 and 0.5. I think the difference in the magnitude might give the NCA an indication of where it is relative to the center.
To isolate the traces, simply double-click on the legend. To add a trace, click on the desired label.
Code
import numpy as npfrom PIL import Imageimport imageioimport matplotlib.pyplot as pltimport matplotlib.cm as cm# Your datadata = np.random.rand(50, 10, 10, 16)#data = np.load('gifs_folder/no_damage_state_grid_cache.npy')data = np.load('./data/state_grid_cache.npy')data = np.transpose(data, (0, 2, 3, 1)) # turn to (time, height, width, channel)#data = (data + 1.)/2.# Ensure the data is in the range [0, 1]pixel_at = (56//2, 56//2)data_at_pixel = data[:, pixel_at[0], pixel_at[1], :]# use plotly to plot each channel and also where the pixel is located on the emojiimport plotly.graph_objects as gofig = go.Figure()for channel inrange(data_at_pixel.shape[-1]): fig.add_trace(go.Scatter(x=np.arange(data_at_pixel.shape[0]), y=data_at_pixel[:, channel], mode='lines', name=f'channel {channel}'))# add title and axis labelsfig.update_layout(title='Evolution of each channel at pixel (28, 28) - the center of the emoji', xaxis_title='time', yaxis_title='channel value')fig.show()pixel_at = (56//2, 56-38 ) data_at_pixel = data[:, pixel_at[0], pixel_at[1], :]# plot another at a different pixel also plot where the pixel is located on the emoj, use a subplot to plot both plots side by sidefig = go.Figure()for channel inrange(data_at_pixel.shape[-1]): fig.add_trace(go.Scatter(x=np.arange(data_at_pixel.shape[0]), y=data_at_pixel[:, channel], mode='lines', name=f'channel {channel}'))# add title and axis labelsfig.update_layout(title=f'Evolution of each channel at pixel {pixel_at} - half way between the center and the edge of the emoji', xaxis_title='time', yaxis_title='channel value')fig.show()pixel_at = (56//2,56-45 ) data_at_pixel = data[:, pixel_at[0], pixel_at[1], :]# plot another at a different pixel also plot where the pixel is located on the emoj, use a subplot to plot both plots side by sidefig = go.Figure()for channel inrange(data_at_pixel.shape[-1]): fig.add_trace(go.Scatter(x=np.arange(data_at_pixel.shape[0]), y=data_at_pixel[:, channel], mode='lines', name=f'channel {channel}'))# add title and axis labelsfig.update_layout(title=f'Evolution of each channel at pixel {pixel_at} - at the edge of the emoji', xaxis_title='time', yaxis_title='channel value')fig.show()
Conclusion
In conclusion, the Neural Cellular Automata (NCA) system demonstrates that one can train a collective of simple agents to perform complex tasks. The NCA system’s ability to learn and adapt to its environment is a testament to the power of emergent intelligence and its remarkable resilience and ability to regenerate from unexpected damage highlights its intriguing potential.
The intelligence found within cells and organisms offers valuable lessons and opportunities for advancements in artificial intelligence. The application of the NCA system to complex tasks, such as the Self-classifying MNIST Digits project (Randazzo et al. 2020), showcases the potential of the NCA system to be applied to real-world problems.
While the NCA system may face challenges, such as difficulties in regeneration amidst significant distortions, I firmly believe in the promising inherent emergent intelligence it possesses. These observations can potentially contribute to enhancing the robustness of AI systems, particularly in their ability to handle noise (Goodfellow, Shlens, and Szegedy 2014) and make recurrent decisions.
Thanks for reading! I hope you enjoyed this article. If you have any comments, please leave them below. 😊📝👇
References
Goodfellow, Ian J, Jonathon Shlens, and Christian Szegedy. 2014. “Explaining and Harnessing Adversarial Examples.”arXiv Preprint arXiv:1412.6572.
Mordvintsev, Alexander, Ettore Randazzo, Eyvind Niklasson, and Michael Levin. 2020. “Growing Neural Cellular Automata.”Distill. https://doi.org/10.23915/distill.00023.
Randazzo, Ettore, Alexander Mordvintsev, Eyvind Niklasson, Michael Levin, and Sam Greydanus. 2020. “Self-Classifying MNIST Digits.”Distill. https://doi.org/10.23915/distill.00027.002.